ReSTIR GI总结
ReSTIR GI 小总结
ReSTIR DI
用ReSTIR做直接光照。
RIS - Resampled Importance Sampling 重要性重采样
要解决的问题是:我想要采样target pdf $\hat{p}$,但是不好采(inversion sampling的条件不满足等等等,导致没办法直接采)。但是我有一个还不错的source pdf $p$,和target pdf有点像,优点在于好采。
workflow:使用source pdf $p$ 生成M个candidate samples,记作$x_i, 1 \le i \le M$。接下来在这M个候选样本中按权重再采一次样。样本$x_i$的权重是 $w_i = \frac{\hat{p}(x_i)}{p(x_i)}$. 如此得到最终的采样点$x$.
需要注意的是采样点$x$的分布并不完全服从$\hat{p}$,事实上对应另一个pdf,不妨叫做effective pdf. 当$M=1$时,effective pdf完全等同于source pdf;当$M \rightarrow \inf$的时候,effective pdf等同于target pdf。实际中$M$是一个有限的值,因此effective pdf是对target pdf一个较好的近似。
直接光照中,需要计算$L_o(y, w) = \int_H f(y, x\rightarrow y, \vec{w}) L_i(p, x\leftrightarrow y) G(x \leftrightarrow y) V(x \leftrightarrow y) \mathrm{d}A_x$
其中$y$是着色点,$x$是在光源上的采样点。高质量的采样点的pdf应该和integrand的形状相似,这样才收敛得快。论文中取$f(y, x\rightarrow y, \vec{w}) L_i(p, x\leftrightarrow y) G(x \leftrightarrow y)$为target pdf,即仅仅没有考虑visibility这一项(由于RIS的良好性质,target pdf并不需要normalize,因为最后反正是按$w_i$这个权重对候选点采样,normalize仅仅是将所有的权重等比例地放大/缩小,没啥意义,所以直接用这个式子做target pdf是可以的)。source pdf这样取:首先根据场景中光源的intensity大小作为权重采一次样,得到一个光源。再在这个光源的表面均匀采样,得到光源上的一个点。因此source pdf是和光源的亮度成正比的。
由此$\hat{p}$和$p$都已经确定,最终的estimator为
该estimator无偏的条件为:$M$ 和 $N$ 均为正且 $f(x_{j}) > 0 \rightarrow p(x_j)>0 \And \hat{p}(x_j) > 0$.
该estimator与重要性采样在形式上的差距主要在于要乘 $\frac{1}{M} \sum_{j=1}^M w(x_{j})$ 来做修正,因为 $y$ 并非由 $\hat{p}$ 直接采出。
在进行多次采样的情况下,estimator对每次采样的结果做平均
采样了 $N$ 个点,每次采样一个点的时候都生成了 $M$ 个candidates。在第$i$ 次采样中,候选样本为$x_{ij}, 1\le j \le M$, 采样得到的点是$y_i$。这是一个修正项,因为$y_i$的实际分布并非$\hat{p}$,这一项使得该estimator无偏。
WRS - Weighted Reservoir Sampling
如果直接用RIS,那么每个像素处都要维护自己的 $M$ 个candidates. 矛盾在于 $M$ 越大,RIS得到的采样点分布越接近于target pdf,渲染效果越好,但是存储开销也会增大。使用蓄水池采样的好处在于:使存储开销为常量。在不使用蓄水池的时候,存储开销随 $M$ 线性增加;使用蓄水池的时候,每个像素处只需要存储一个蓄水池,开销为常量。并且使用蓄水池时可以很方便地进行时空复用,详见后文。
- 问题:从一系列候选点$x_i$中按权重$w_i$进行采样。从$i=1$开始流式地对这$M$个样本做处理。
解法:定义一个结构体reservoir,其成员有y(最终样本)和w_sum(当前已经处理的candidates的权重之和)。已经处理了 $i$ 个candidates后,其满足该性质:$\forall k \le i,P(y=x_k)=\frac{w_k}{w_{sum}}$,也就是相当于对这 $i$ 个candidates按权重做了采样得到了 $y$ . 对新进入的 $x_{i+1}$,进行如下的更新操作:以 $P(y=x_{i+1} | y=x_k) = \frac{w_{i+1}}{w_{sum}+w_{i+1}}$ 的概率将 $y$ 更新为 $x_{i+1}$(否则 $y$ 保持原来的值),随后将 $w_{sum}$加上$w_{i+1}$更新为$w’_{sum}$。这样,处理完新的这个样本之后,原来的性质仍然满足:$\forall k \le i, P(y=x_k)=\frac{w_k}{w_{sum}} * (1-\frac{w_{i+1}}{w_{sum}+w_{i+1}}) = \frac{w_k}{w’_{sum}}$。
如此,在保证只需要一个reservoir的存储空间的情况下,对M个candidates做了流式处理,按权重采样到了一个点$y$。
- 合并reservoir时的一个优良性质:
对两个reservoir $r_{1}$ (处理了$M_1$个candidates)和$r_2$(处理了$M_2$个candidates),将$r_2$视作一个新的权重为 $w_{sum2}$ 的样本点,按照reservoir的更新方法 $\text{r1.update}(r2)$ 得到更新后的 $r_1$ 。该方法所得到的 $r_1$ 所代表的分布,和一开始只有 $r_1$,然后依次处理 $r_2$ 中的 $M_2$ 个样本点所得到的 $r_{1}’$ 的概率分布是一样的。这样就在 $O(1)$ 的时间里把$r_1$的candidates数量从$M_1$提高到了$M_1+M_2$。后边可以看到,利用这个性质可以使候选点的数量指数级提升。当我们取周围的 $k$ 个reservoir进行复用的时候,每次复用使得候选点数量增加 $M$,可以在 $O(k)$ 的时间里增加到 $(k+1) \cdot M$ 个候选点。
算法流程
在每个像素处,先建一个reservoir,采样M=32个初始样本(按照光源的intensity作为权重进行采样)。
时间复用,计算motion vector找到上一帧对应的像素,把上一帧像素的reservoir合到本像素的reservoir里边,完成时间复用。
空间复用。循环n次,每次循环中,loop over每个像素,在以本像素为圆心,半径为30像素(30这个值仅仅用于举例,取一个适中的距离)的圆内部随机采样k个邻居,并把它们的reservoir合到自己的reservoir当中。这样就相当于我以 $O(nk)$的复杂度(n次循环,每个像素取k个邻居)得到了一个有 $(k+1)^n \cdot M$ 个candiadtes的超级reservoir(每次循环候选点数量提升 $k+1$ 倍,一共n次),候选点数量随循环次数指数级提升,有望得到较高的渲染质量。
最后每个像素处所得到的reservoir里边的 $y$ 就是最终的高质量样本。这个采样点 $y$ 在某个光源上。从着色点出发往 $y$ 去trace一条shadow ray,计算直接光的贡献。根据estimator得到radiance的估计值。
ReSTIR GI
同样使用RIS和WRS相结合的方式来提升采样点的质量。区别在于,ReSTIR DI的采样点都在光源上,主要用于提升shadow ray的质量;ReSTIR GI的采样点在场景中,主要用于提升indirect ray的质量
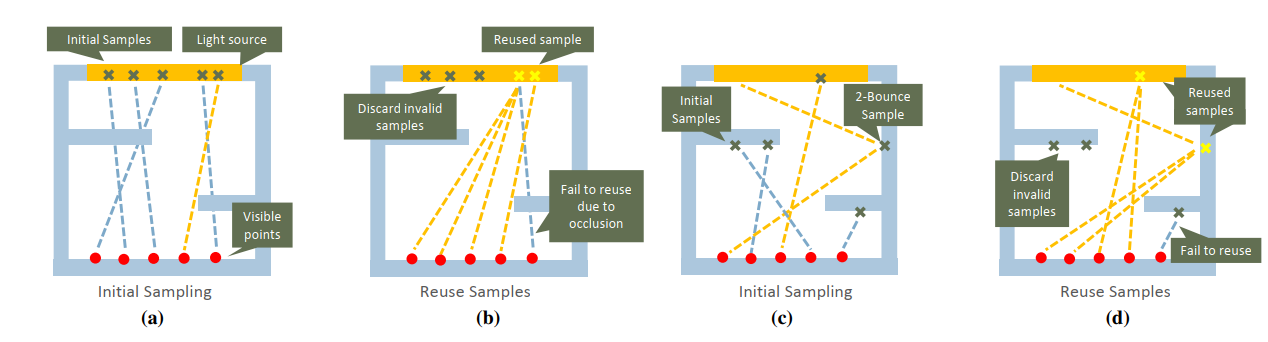
在上图中
- (a) 此时是ReSTIR DI中在每个像素生成样本之后的情况。红色点表示visible points,也就是能够直接从摄像机看到的点。叉叉表示各个像素(也就是visible point)的蓄水池所对应的样本。
- (b) 经过时空复用后,各个visible point都选取了更优的样本。
- (c) 在ReSTIR GI中生成样本之后的情况。类似的,图中的红点表示visible point,叉叉表示sample point.
- (d) 在经过时空复用后,各个visible point都选择了更优的样本点。
算法流程
生成样本
首先从摄像机出发,各个像素有对应的可见点visible point(可以用光栅化,也可以光追)。在visible point处根据所自己选择的一个source pdf $p$(可以是均匀的,也可以是cosine-weighted的,也可以根据visible point处的bsdf采样)采样一个方向,沿该方向发射一条光线,得到一个交点,称为sample point。同时需要计算从sample point射到visible point的radiance $L_o(x_s, -w_i)$。在论文中,这个radiance的计算使用基于NEE的路径追踪+MIS完成(这也是计算开销的主要来源,毕竟realtime ray tracing里边每个像素还是只能算一条光线的)。
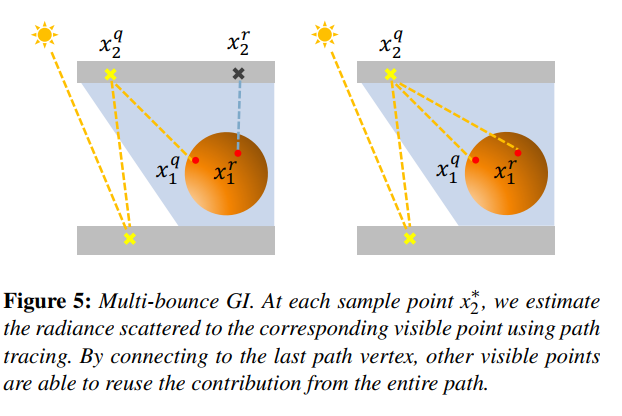
一个重要的假设是,sample point处往各个方向射出的radiance是相同的(即purely diffuse),等于用路径追踪算出的 $L_o(x_s, -w_i)$ (sample point往visible point射出的radiance)。这是进行空间复用的基础:如下图,本来只计算了 $x_{2}^q$ 射向 $x_{1}^r$ 的radiance,而空间复用的时候又把这个值用到了其它的visible point $x_1^q$ 上,没有这个假设的话,就很难在visible point之间做样本点的复用了。需要注意的是这只假设了sample point处是purely diffuse,而整个光路中其它的vertex都依旧使用的是其本身的bsdf(从光源到sample point之前用的准确的路径追踪,计算visible point的着色的时候用了visible point的bsdf,也是准确的)。那么当sample point真实的bsdf和purely diffuse差得很远的时候,计算结果与真实值就会有较大偏差。
算法流程
和ReSTIR DI类似,有3个buffer. 分别用来存当前帧生成的reservoir,temporal reuse的reservoir,以及spatial reuse的reservoir.
根据方程
选择一个target pdf $\hat{p}$,可以选 $\hat{p} = L_o(x_s, -w_i)$ (也可以把bsdf和cos值带上,但paper里说单独取这个radiance已经够好了,因为它可以保留对其它像素也有效的样本),即从sample point处的outgoing radiance。然后结合 source pdf $p$ 计算initial sample的weight。
时间复用。对于像素q,通过temporal reprojection在temporal buffer里边找到q在上一帧对应的的reservoir,然后把q的initial sample合进去,并将结果放回q对应的temporal reservoir buffer里边
空间复用。迭代k次,每次迭代从像素q周围随机采样一个像素p,从p的temporal buffer里边拿出reservoir,然后合入q的spatial buffer。
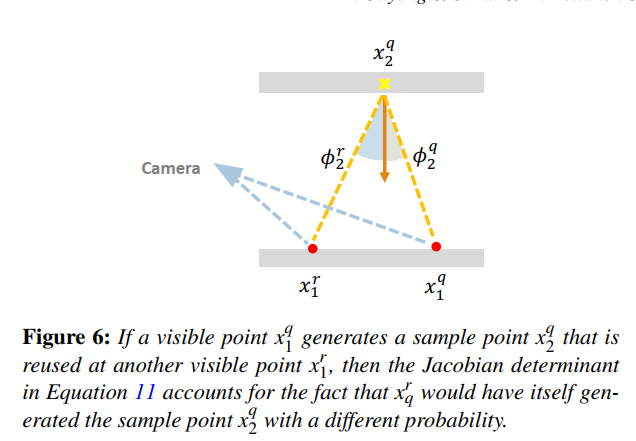
由于局部几何上的差异,像素p和像素q处的source pdf是不一样的(因为计算weight的时候用的是p处的立体角,现在我们要复用到q上,其weight应当对应q的立体角),因此不能直接复用像素p的样本到像素q上,而需要对立体角的概率分布做一个转换,也就是除以一个jacobian determinant。
为了减少空间复用带来的误差,合入之前要进行几何相似性检测,不通过检测的reservoir不合入。相似性检测的具体内容为检查法线方向的夹角和深度值的差异。
最后在每个像素处得到了一个winner sample. 使用RIS estimator去计算估计值即可。
误差 (这节没有认真看呜呜呜以后补)